100% Good Fit Guarantee
Love your tutor or it's free. Guaranteed.
Our belief is that tutoring should be an easy & positive experience for all parties involved -parents, students & tutors. Home tuition is so popular because it works. There is just no substitute for tailored on-on-one help from a maths tutor who gets to know your child's strengths and weaknesses inside out.
Refine your search:
 Maths
Maths English
English Chemistry
Chemistry Physics
Physics Biology
Biology Economics
Economics Naplan
Naplan SACE
SACE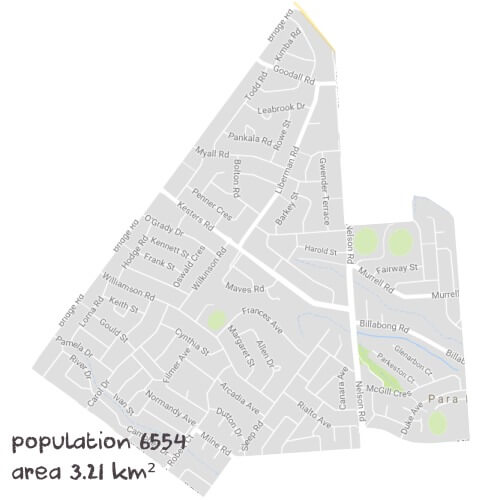

Love your tutor or it's free. Guaranteed.

Carefully screened, fewer than 10% are good enough to work with us.

No booking fees, no hidden fees. Cancel any time, no lock-in.

You decide where and when to meet. As little or as often as you want.

All tutors have a valid working with children check

Reach goals and improve grades faster with private, 1-to-1 lessons.

High school or primary, you'll get a tutor that fits your needs.

Our tutors show WHAT to study + HOW to study

You'll get feedback on each lesson, so you know how your child gets on.











We`ll contact you to organize the first lesson









Our belief is that tutoring should be an easy & positive experience for all parties involved -parents, students & tutors. Home tuition is so popular because it works. There is just no substitute for tailored on-on-one help from a maths tutor who gets to know your child's strengths and weaknesses inside out. Unfortunately such a person can be difficult to find - that's where we come in!

We work with 111 maths tutors in & around Para Hills, SA. The tutor comes to your home, or any other location, to help your child at a time and day that works for you. These tutors have helped thousands of students in both primary and high school - you can look at hundreds of reviews below. They have all been screened, interviewed and most importantly they love tutoring.
Give us a call on 1300 312 354 Or complete the enquiry form below. We'll have a quick chat to understand your needs and figure out which times/days work best. Then we'll organise a tutor to get in touch for a trial risk-free lesson. Simple.