100% Good Fit Guarantee
Love your tutor or it's free. Guaranteed.
Most parents appreciate that there is little more important than educating and enabling their children. This is one of our core values - Education Is Life! Whether your child needs a bit of help keeping up or wants to get an ATAR of 99.95, they'll need the right support to get there.
Refine your search:
 Maths
Maths English
English Chemistry
Chemistry Physics
Physics Biology
Biology Economics
Economics Naplan
Naplan QCE
QCE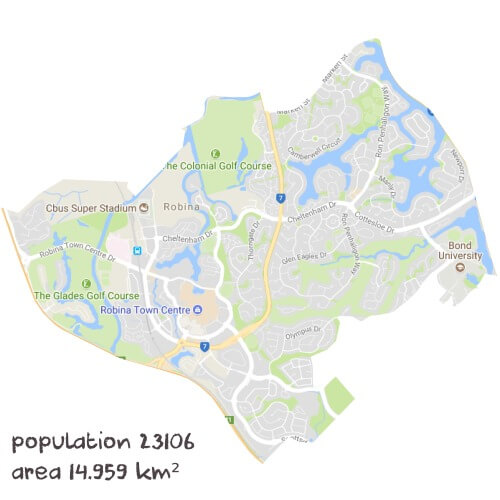

Love your tutor or it's free. Guaranteed.

Carefully screened, fewer than 10% are good enough to work with us.

No booking fees, no hidden fees. Cancel any time, no lock-in.

You decide where and when to meet. As little or as often as you want.

All tutors have a valid working with children check

Reach goals and improve grades faster with private, 1-to-1 lessons.

High school or primary, you'll get a tutor that fits your needs.

Our tutors show WHAT to study + HOW to study

You'll get feedback on each lesson, so you know how your child gets on.
















We`ll contact you to organize the first lesson


Most parents appreciate that there is little more important than educating and enabling their children. This is one of our core values - Education Is Life! Whether your child needs a bit of help keeping up or wants to get an ATAR of 99.95, they'll need the right support to get there. There are 62 maths tutors in Robina, QLD who can help with that - from problem solving to study habits. Check out hundreds of reviews below - these tutors do a great job.

Private tutoring is all about getting the right person who fits well with your child's unique needs and personality. That's where we come in. We'll put you in touch with a maths tutor and organise a trial lesson. If you don't like it, we won't charge you. And because we like to keep things simple, there are no booking fees, cancellation costs, minimum requirements, there's no nonsense. Just use what you need based on a simple hourly rate.
Call us on 1300 312 354 OR complete an enquiry form and we'll reach out to you!